





AI再度进化:微软模仿人类来训练人工智能

近日,微软研究人员开发了一种AI系统,通过模仿人类增进对世界了解的方式来训练图像-文本对,即人工智能的一种。
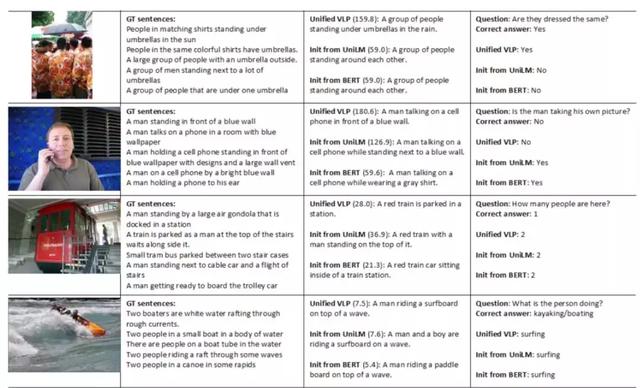
Unified VLP :“一群人撑着伞站在雨中。”
Question :“他们穿的都一样吗”?
Unified VLP : “是的。”
众所周知,没有详细的随附注释,机器人很难理解场景和语言。
但是标记通常耗时久、成本高,且最好的标记也只能传达对场景的理解,不能传达对语言的理解。
为了解决该问题,微软开发了此系统。
研究人员表示,单模型编码器/解码器视觉语言预训练(VLP)模型既可以生成图像描述,又可以回答有关场景的自然语言问题,为将来可能达到人类同等水平奠定了基础。
GitHub上提供了使用三百万个图像-文本对进行预训练的模型。
GitHub:https://github.com/LuoweiZhou/VLP
“对周围世界的感知是我们从小就开始学习的一种技能……我们与身体环境的互动越多……就越能理解和使用语言来解释存在的事物”微软高级研究员Hamid Palangi在博客中写道。
“另一方面,对于机器而言,场景理解和语言理解非常具有挑战性,特别是在弱监督的情况下,本质上来说,能够被间接学习的人很好地利用。”
正如Palangi及其同事所解释的那样,图像字幕和视觉问答质量算法通常表现不佳,原因如下:
(1)无法利用上下文描述图像并进行推理;
(2)没有利用大规模的训练数据进行预训练;
(3)架构在设计语言,视觉对齐和语言生成任务时表现不佳。
该团队对包含编码器(学习给定数据的数字表示形式)和解码器(将编码器的表示形式转换为人类可解释的信息)的架构进行了预训练,并针对两种预测进行了优化。
研究人员表示,该架构最终创建了更好地对齐的编码器和解码器表示形式,使他们可以用相同的模型来实现不同的目标,如图像字幕和视觉问题回答。
微软发布新AI:能生成图像描述,还能回答场景相关问题
研究人员评估了VLP在公开基准(包括COCO,Flickr30K和VQA 2.0)上对图片进行说明和推理的能力。
研究人员表示,VLP不仅在几个图像标题和视觉问题回答指标方面优于最新模型,而且还设法回答了与先前模型有关的图像问题(例如与服装设计相似的图像),而之前只接受过语言训练的模型很难回答这些问题。
“通过智能模型设计和智能数据选择,我们可以利用现有的公共资源,在语言和场景理解方面达到更高的水平,VLP就是证明,” Palangi写道。
“通过VLP,我们展示了统一模型在语言和场景理解水平的潜力,这是成功完成各种不同的下游任务所必需的——单个模型在不牺牲性能的情况下高效地完成多个任务。
这意味着更有效,更强大的视觉语言系统,无需花费多个单独训练的模型来达到相同的目标。”
在未来的工作中,该团队将强化模型的架构,同时在预训练期间添加更多数据。

好的文章,需要您的鼓励
2

- 最新资讯
- 最新问答
-
未来已至:Figure 02机器人引领AI硬件新时代
关键字: 人形机器人 2024-08-13 -
配天观点:具身智能商业化落地之路,道阻且长,但行则必至!
关键字: 配天 具身智能 2024-08-09 -
具身智能:人工智能新纪元,赋能未来科技新引擎
关键字: 具身智能 泰科机器人 2024-07-25 -
科技与艺术交融,BrainCo智能仿生手亮相北京中国国家博物馆丨设计智造与高质量发展特展
关键字: 强脑科技 智能仿生手 2024-07-22 -
保障六维力传感器在医疗机器人使用中的数据安全和隐私保护
关键字: 六维力传感器 鑫精诚 2024-07-18
-
amr机器人是什么意思
标签: amr机器人,什么意思 提问:HYN 2024-09-18 11:16:05 -
上海视觉设备厂家有哪些?
标签: 视觉设备,视觉设备厂家 提问:GIGI 2024-09-13 10:16:02 -
搬运机器人多少钱一台?
标签: 搬运机器人,多少钱 提问:小仙 2024-09-10 11:28:02 -
配天机器人价格怎么样?
标签: 配天,机器人,价格 提问:SOSO 2024-09-09 10:48:02 -
场景感知技术包括哪些
标签: 场景感知,技术 提问:YUMI 2024-09-03 10:30:05


- 2019-12-10 15:56:01
- 2019-02-25 14:09:23
- 2018-11-01 08:55:18
- 2016-05-24 08:00:00
- 2021-05-20 13:31:10
- 2021-06-10 11:10:21
- 2022-11-14 16:16:05
- 2022-09-15 10:03:04
- 2022-09-02 12:17:08
- 2023-03-12 10:30:47
- 2022-11-21 15:57:36
- 2022-09-13 16:28:57
- 2024-08-13
- 2024-08-09
- 2024-07-25
- 2024-07-22
- 2024-07-18
- 2024-07-18
- 2024-07-18
- 2024-01-29
- 2024-01-16
- 2024-01-10









