





使用像素差异识别自动驾驶的深度

有许多传感器可用于在车辆行驶时捕获信息。捕获的各种测量结果包括速度,位置,深度,热等。这些测量结果被输入到反馈系统中,该系统训练并利用运动模型来遵守车辆。本文重点介绍通常由LiDAR传感器捕获的深度预测。LiDAR传感器使用激光捕获与物体的距离,并使用传感器测量反射光。但是,对于日常驾驶员而言,LiDAR传感器是负担不起的,那么还能如何测量深度?将描述的最新方法是无监督的深度学习方法,该方法使用一帧到下一帧的像素差异或差异来测量深度。
请注意图像标题,因为大多数图像均来自所引用的原始论文,而不是我自己的产品或创造。
Monodepth2
[1]中的作者开发了一种方法,该方法使用深度和姿势网络的组合来预测单个帧中的深度。通过在一系列帧上训练自己的体系结构和一些损失函数来训练两个网络来实现。此方法不需要训练的基本事实数据集。相反,它们使用图像序列中的连续时间帧来提供训练信号。为了帮助限制学习,使用了姿势估计网络。在输入图像与从姿势网络和深度网络的输出重建的图像之间的差异上训练模型。稍后将更详细地描述重建过程。[1]的主要贡献是:
1、一种自动遮罩技术,可消除对不重要像素的聚焦
2、用深度图修改光度重建误差
3、多尺度深度估计
建筑
本文的方法使用深度网络和姿势网络。深度网络是经典的U-Net [2]编码器-解码器体系结构。编码器是经过预训练的ResNet模型。深度解码器类似于先前的工作,在该工作中,它将S型输出转换为深度值。
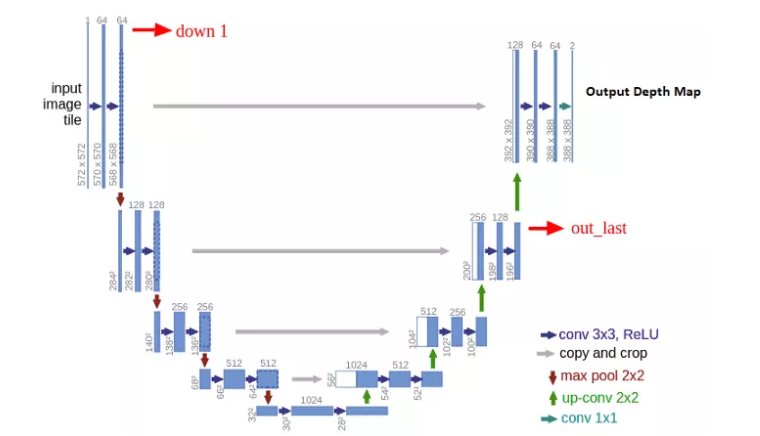
U-Net的样本图像[2]
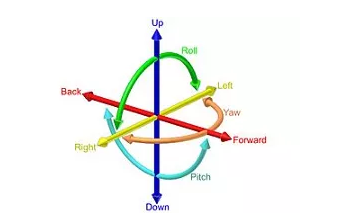
6自由度
作者使用来自ResNet18的姿势网络,该姿势网络经过修改,可以将两个彩色图像作为输入来预测单个6自由度相对姿势或旋转和平移。姿势网络使用时间帧作为图像对,而不是典型的立体声对。它从序列中的另一幅图像的角度预测目标图像的外观,该序列是前一帧还是后一帧。
训练
下图说明了该体系结构的训练过程。
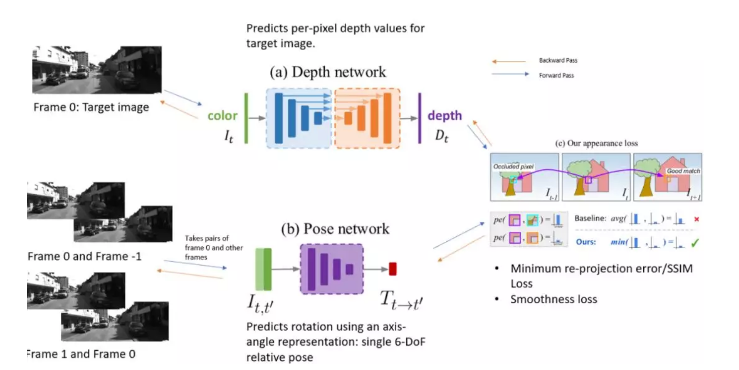
图像取自KITTI和[1]
光度重建误差
目标图像位于第0帧,并且用于预测过程的图像可以是前一帧或后一帧,因此,帧+1或帧-1。该损失是基于目标图像和重建的目标图像之间的相似性。重建过程通过使用姿势网络从源帧(帧+1或帧-1)计算转换矩阵开始。这意味着正在使用有关旋转和平移的信息来计算从源帧到目标帧的映射。然后,使用从深度网络预测的目标图像的深度图和从姿势网络转换的矩阵,将其投影到具有固有矩阵K的摄像机中,以获取重建的目标图像。此过程需要先将深度图转换为3D点云,然后再使用相机内在函数将3D位置转换为2D点。所得的点用作采样网格,以从目标图像进行双线性插值。
这种损失的目的是减少目标图像和重建的目标图像之间的差异,在目标图像和重建的目标图像中,姿势和深度都需要。

来自[1]的光度损失功能

使用最小光度误差的好处。带圆圈的像素区域被遮挡。图片来自[1]。
通常,类似的方法将重投影误差平均到每个源图像中,例如帧+1和帧1。但是,如果一个像素在这些帧之一中不可见,但是由于它靠近图像边界或被遮挡而在目标帧中,则光度误差损失将非常高。为了解决与此相关的问题,他们对所有源图像采取最小的光度学误差。
自动掩码
最终的光度损耗乘以一个掩码,该掩码可解决与假设照相机在静态场景中移动(例如,某个对象以与照相机类似的速度移动或当其他对象处于静止状态时照相机已停止)移动的假设有关的变化问题移动。这种情况的问题是深度图可预测无限深度。作者使用一种自动遮罩方法解决了这一问题,该方法可以过滤不会将外观从一帧更改为下一帧的像素。使用二进制生成掩码,如果目标图像和重建的目标图像之间的最小光度误差小于目标图像和源图像的最小光度误差,则为1;否则为0。
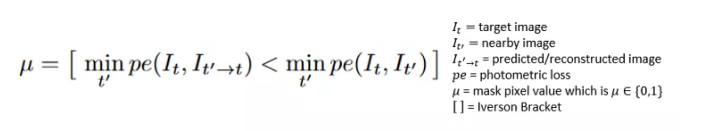
[1]中的自动遮罩生成,其中Iverson方括号为 true时返回1,否则为0。
当相机是静态的时,结果是图像中的所有像素都被掩盖了。当物体以与照相机相同的速度移动时,会导致图像中静止物体的像素被掩盖。
多尺度估计
作者将各个规模的个别损失合并在一起。将较低分辨率的深度图上采样到较高的输入图像分辨率,然后在较高的输入分辨率下重新投影,重新采样并计算光度误差。作者声称,这限制了各个比例尺上的深度图以实现相同的目标,即对目标图像进行精确的高分辨率重建。
其他损失
作者还在平均归一化的反深度图值和输入/目标图像之间使用了边缘感知的平滑度损失。这鼓励模型学习尖锐的边缘并消除噪声。
最终损失函数变为:
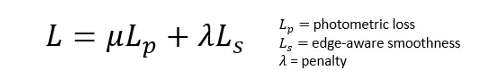
[1]中的最终损失函数在每个像素,比例和批次上平均。
结果
作者在包含驱动序列的三个数据集上比较了他们的模型。在所有实验中,方法均胜过几乎所有其他方法。下图显示了它们的性能示例:

图片来自[1]
Monodepth2扩展名:Struct2Depth
对象运动建模
来自Google大脑的作者发表了[3],该书进一步扩展了Monodepth2。它们通过预测单个对象而不是整个图像的运动来改善姿势网络。因此,现在重建的图像序列不再是单个投影,而是组合在一起的一系列投影。通过两个模型,一个对象运动模型和一个自我运动网络(类似于前面几节中描述的姿势网络)来做到这一点。步骤如下:

Mask R-CNN [2]的样本输出。图片来自[2]
1、预训练的遮罩R-CNN [2]用于捕获潜在移动物体的分割。
2、使用二进制掩码从静态图像(帧-1,帧0和帧+1)中删除这些可能移动的对象
3、被掩盖的图像被发送到自我运动网络,并输出帧-1和0与帧0和+1之间的转换矩阵。
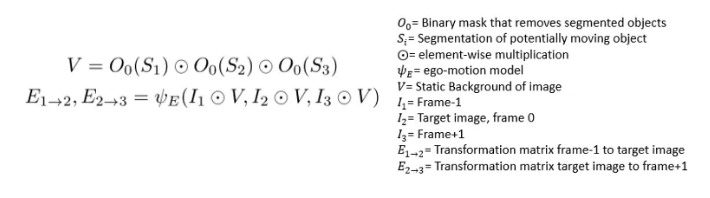
遮罩过程可提取静态背景,然后提取自我运动转换矩阵,而无需移动对象。来自[3]的方程。
1、使用步骤3中产生的自我运动转换矩阵,并将其应用于帧-1和帧+1,以获取变形的帧0。
2、使用从步骤3得到的自我运动变换矩阵,并将其应用于可能移动的对象的分割蒙版到帧-1和帧+1,以获取每个对象都针对帧0的扭曲的分割蒙版。
3、二元掩码用于保持与变形分割掩码关联的像素。
4、蒙版图像与变形图像组合在一起,并传递到对象运动模型,该模型输出预测的对象运动。
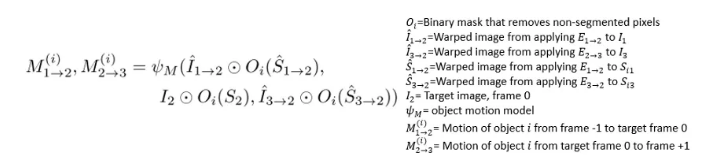
一个对象的对象运动模型。来自[3]的方程
结果表示了相机必须如何移动才能“解释”对象外观的变化。然后,要根据对象运动建模过程的步骤4中生成的运动模型来移动对象。最后,将变形的对象运动与变形的静态背景结合起来,以获得最终的变形:

来自[3]的方程

图片来自[5]
学习对象量表
虽然Monodepth2通过其自动遮罩技术解决了静态物体或以与照相机相同速度移动的物体的问题,但这些作者还是建议对模型进行实际训练,以识别物体的比例,从而改善物体运动的建模。

图片来自Struct2Depth。中间一栏显示了无限深度分配给以相同相机速度移动的对象的问题。第三列显示了他们改进此方法的方法。
它们基于对象(例如房屋)的类别定义每个对象的比例尺的损失。它旨在基于对象比例尺的知识来限制深度。损失是图像中对象的输出深度图与通过使用相机的焦距,基于对象类别的先验高度和图像中分割后的对象的实际高度计算出的近似深度图之间的差,两者均按目标图片的平均深度进行缩放:

损耗的公式可帮助模型学习对象比例。来自[3]的方程。
结果
将[3]中描述的扩展与Monodepth2模型直接进行比较,并显示出显着的改进。
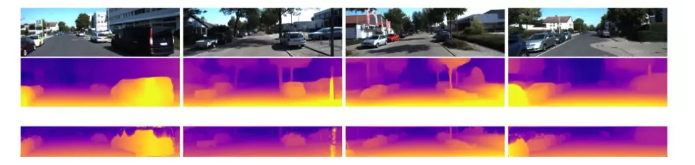
中间的一行显示[3]的结果,而第三行显示的是地面真实情况。图片来自[5]。
摘要
自动驾驶中深度估计的常用方法是使用一对需要两个摄像机的立体图像或一个LiDAR深度传感器。但是,这些都是昂贵的,并不总是可用。此处描述的方法能够训练深度学习模型,这些模型可预测一个图像上的深度,而仅对一系列图像进行训练。它们显示出良好的性能,并为自动驾驶研究提供了广阔的前景。
要尝试自己的模型,两篇论文的存储库都位于下面:
Monodepth2:
https : //github.com/nianticlabs/monodepth2
Struct2Depth:
https : //github.com/tensorflow/models/tree/master/research/struct2depth
参考文献
[1] Godard,C.,Mac Aodha,O.,Firman,M.和Brostow,G.(2018)。挖掘自我监督的单眼深度估计。arXiv预印本arXiv:1806.01260。
[2] Olaf Ronneberger,Philipp Fischer和Thomas Brox。U-Net:用于生物医学图像分割的卷积网络。InMICCAI,2015年。
[3] Vincent Casser,Soeren Pirk,Reza Mahjourian,Anelia Angelova:没有传感器的深度预测:利用单眼视频无监督学习的结构。第三十三届AAAI人工智能会议(AAAI'19)。
[4] He,K.,Gkioxari,G.,Dollár,P.和Girshick,R.(2017)。遮罩r-cnn。在IEEE计算机视觉国际会议论文集(第2961–2969页)中。
[5] 文森特· 卡瑟(Vincent Casser),索恩·皮克(Soeren Pirk),雷扎·马朱里安(Reza Mahjourian),阿内莉亚· 安杰洛娃(Anelia Angelova):无监督的单眼深度和具有结构和语义的自我运动学习。CVPR基于位置线索的视觉里程表和计算机视觉应用研讨会(VOCVALC),2019年

好的文章,需要您的鼓励
2

- 最新资讯
- 最新问答
-
轮式机器人的发展及其趋势
关键字: 轮式机器人 发展 趋势 2024-07-03 -
具身智能的定义和作用
关键字: 具身智能 2024-06-28 -
什么是agv小车?特点有哪些?
关键字: agv小车 特点 2024-06-27 -
机器视觉应用的分类?范围有哪些?
关键字: 机器视觉 应用分类 范围 2024-06-25 -
机器人打磨抛光设备有哪些?特点是什么?
关键字: 机器人打磨 抛光 特点 2024-06-20
-
机器人焊接焊机报TC异常怎么解决
标签: 焊接机器人,焊机,TC异常 提问:TC 2024-06-28 16:05:01 -
机器人运动轨迹的控制方式有哪两种
标签: 机器人,运动轨迹,控制方式 提问:张默 2024-06-25 10:10:02 -
具身智能什么意思
标签: 具身智能,什么意思 提问:MESSE 2024-06-19 10:37:04 -
3D视觉无序抓取系统配置要点?
标签: 3D视觉,无序抓取,系统配置 提问:QUTE 2024-06-17 13:17:05 -
3d相机机器视觉检测原理
标签: 3D相机,视觉检测 提问:木木 2024-06-17 13:03:03


- 2021-06-10 10:45:45
- 2021-06-11 13:34:28
- 2020-05-29 10:03:22
- 2019-09-24 11:19:01
- 2020-01-16 13:27:13
- 2019-03-22 15:42:15
- 2022-08-03 10:20:40
- 2024-06-28
- 2024-06-27
- 2024-06-25
- 2024-06-20
- 2024-06-19
- 2024-06-17
- 2024-06-13
- 2024-06-11
- 2024-06-06
- 2024-06-04









