





谷歌大脑提出TCN,能让机器人边看视频边模仿
时间:2018-02-07
作者:雷锋字幕组
阅读:7309

在Time-Contrastive Networks: Self-Supervised Learning from Multi-View Observation这篇论文中,谷歌的研究者提出了一种从观察中学习世界的新方法,并多角度展示了机器人仅仅通过观看视频,就能在无人监督的情况下,模拟视频动作的全过程。
除了视频演示之外,谷歌大脑并未对机器人系统提供监督学习。他们将这种方法运用于各种不同的任务,以此来训练真实和虚拟机器人。例如,倒水任务,放碟任务,和姿势模仿任务。
第一步
通过视频的分解镜头来学习,将时间作为监督信号,发现视频的不同属性。这组嵌入向量经由一组非结构化和未标记的视频训练,里面含有和任务相关的有效动作,也有一些随机行为,来体现真实世界中的各种可能状态。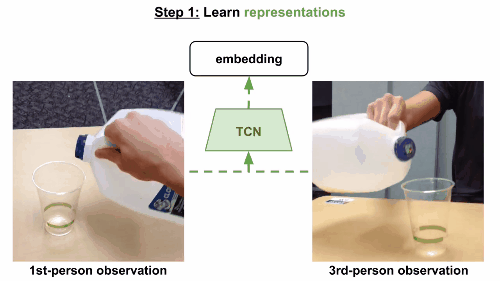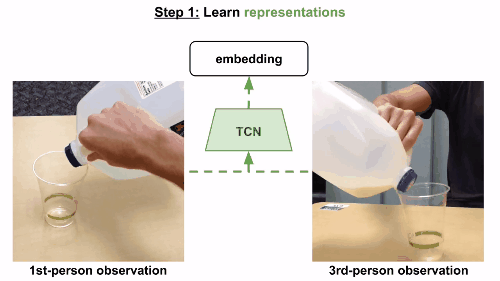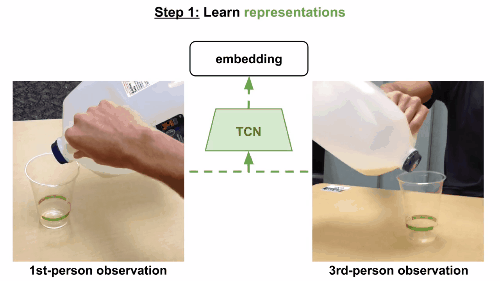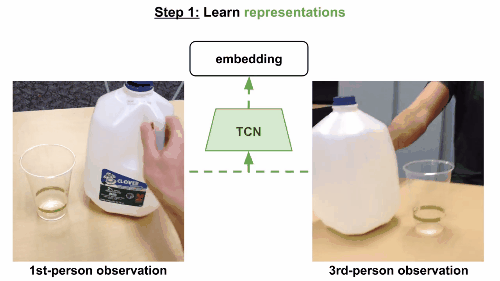
模型使用triplet loss误差函数,基于同一帧的多视角观察数据来训练多视角下同时出现的帧,在嵌入空间中互相关联。当然也可以考虑一个时间对比模型,只根据单一视角来训练。这一次,有效帧在锚点的一定范围内随机选定,根据有效范围计算边际范围。无效范围是在边际范围外随机选定。模型和之前一样进行训练。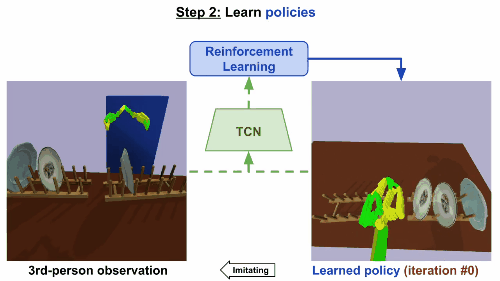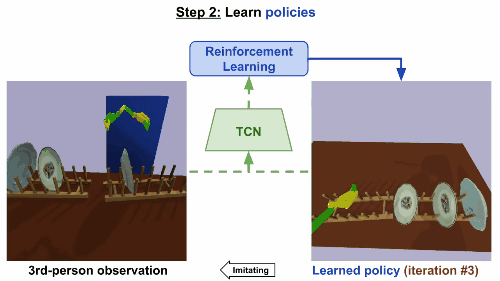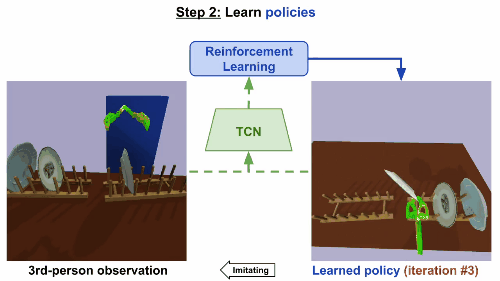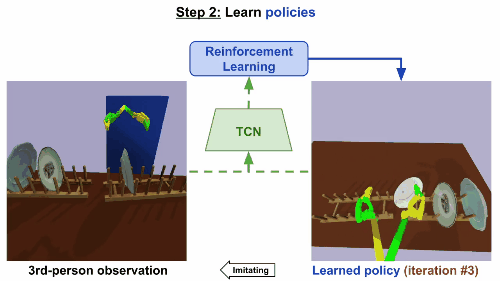
第二步
通过强化学习来学习规则。基于TCN嵌入,根据第三方的真人示范来构造奖励函数。机械臂起初尝试一些随机动作,然后学会反复进行这些动作,就可以产生最高奖励的控制步骤,最后达成重现视频任务的效果。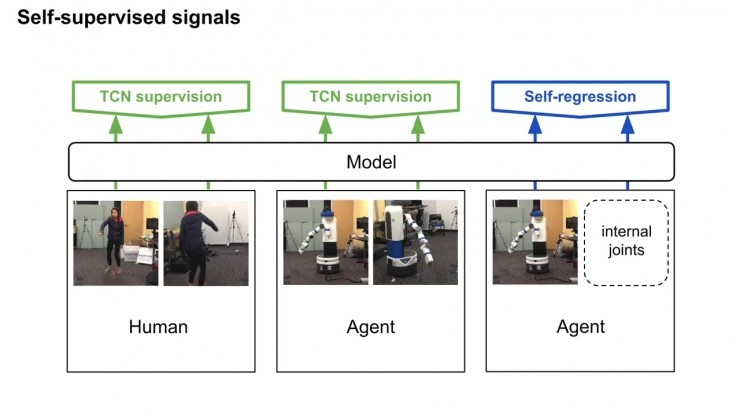
模型在仅仅经历了9次迭代后就成功收敛,大约相当于现实世界15分钟的训练。同样地,在移碟任务中,机器人最初尝试随机运动,然后学会成功拿起和移动一个盘子。
机器人
黑科技

好的文章,需要您的鼓励
15

- 最新资讯
- 最新问答
-
2025两会热议:工业机器人“黄金五年”已来?
关键字: 工业机器人 2025-03-12 -
AI赋能工业机器人,制造业革命,已悄然来临!
关键字: 工业机器人 2025-01-16 -
巅峰对决完美收官!2024年中关村仿生机器人大赛各项冠军出炉!
关键字: 仿生机器人 2024-11-29 -
出海+ | 极智嘉10月全球新动态
关键字: 极智嘉 2024-10-24 -
会议邀请 | 昇视唯盛邀请您参加第8届国际机器人焊接、智能化与自动化会议暨第15届中国机器人焊接会议
关键字: 昇视唯盛 机器人焊接 会议 2024-10-17
-
智能焊接机器人的优势有哪些?
标签: 焊接机器人,工业机器人,配天机器人 提问:小王 2025-06-04 14:03:04 -
自动装卸货机器人的组成部分有哪些?
标签: 赛那德机器人,装卸货机器人,赛那德 提问:李子 2025-05-28 11:03:03 -
激光焊接机器人的特点有哪些?
标签: 激光焊接机器人,焊接机器人,工业机器人 提问:小T 2025-04-15 11:02:00 -
工业机器人码垛原理是什么?
标签: 码垛机器人,工业机器人 提问:晓明 2025-03-24 12:00:00 -
什么是自动焊接和半自动焊接?
标签: 焊接,焊接机器人 提问:小君 2025-03-18 09:00:00
推荐

相关资讯
相关问答
- 2016-08-12 05:07:36
- 2016-08-17 01:22:54
- 2018-01-22 13:33:14
- 2018-04-04 15:23:23
- 2017-06-13 02:31:32
- 2025-04-29 16:26:32
- 2022-08-24 12:09:31
- 2018-07-18 16:14:08
- 2022-08-30 15:17:40
- 2022-08-24 14:16:37
- 2022-09-13 12:17:35
- 2023-09-01 10:16:04
栏目推荐
- 2025-03-12
- 2025-01-16
- 2024-11-29
- 2024-10-24
- 2024-10-17
- 2024-10-16
- 2024-10-16
- 2024-10-16
- 2024-10-15
- 2024-10-15









